Wrattler: Interactive, smart
and polyglot notebooks
Tomas Petricek, The Alan Turing Institute
W
R
A
T
T
L
E
R
W Wrangle
R Reproduce
A Analyse
T Transform
T Troubleshoot
L Learn
E Explore
R Revise
What makes data science hard?
Big data is big
Hard-to-find special cases
The Double Anna Karenina principle
Every data set is different
Feedback loops everywhere
Can't say what works until we've done it
Death by a thousand cuts
Many tasks are repetitive
Data science
What tools do we need?
Interactive – give quick feedback
Reproducible – be able to go back
Polyglot – mix tools that work
Smart – get help from the AI
Explainable – no black boxes
DEMO
Analysing broadband speed in Wrattler
https://wrattler.github.io/wrattler/broadband.html
Traditional notebook architecture

1 Limited reproducibility
2 No rollback of state
3 Limited interaction model
4 One language per kernel
Wrattler system architecture
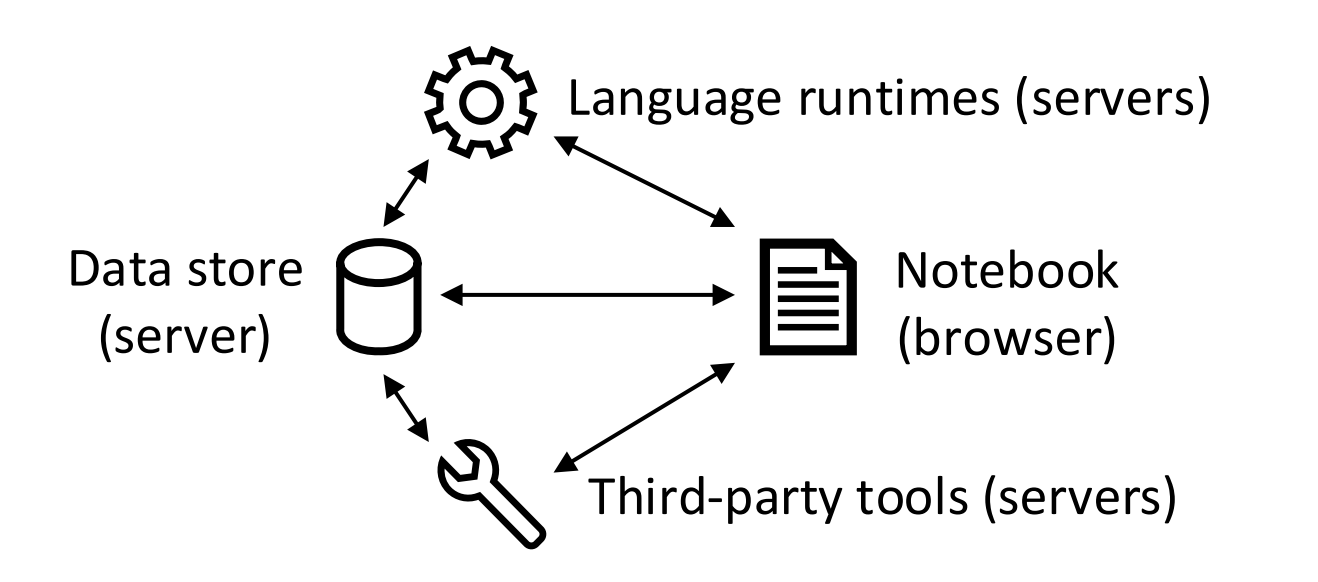
Wrattler system architecture
1 Versioning and provenance
2 Interactive development
3 Platform for AI assistants
4 Polyglot programming
Wrattler
Noteboks that are 1 interactive 2 smart and 3 polyglot
1 Interactive
Tighter interaction feedback loop
Browser-based language
Recalculated on-the-fly
Using dependency graph
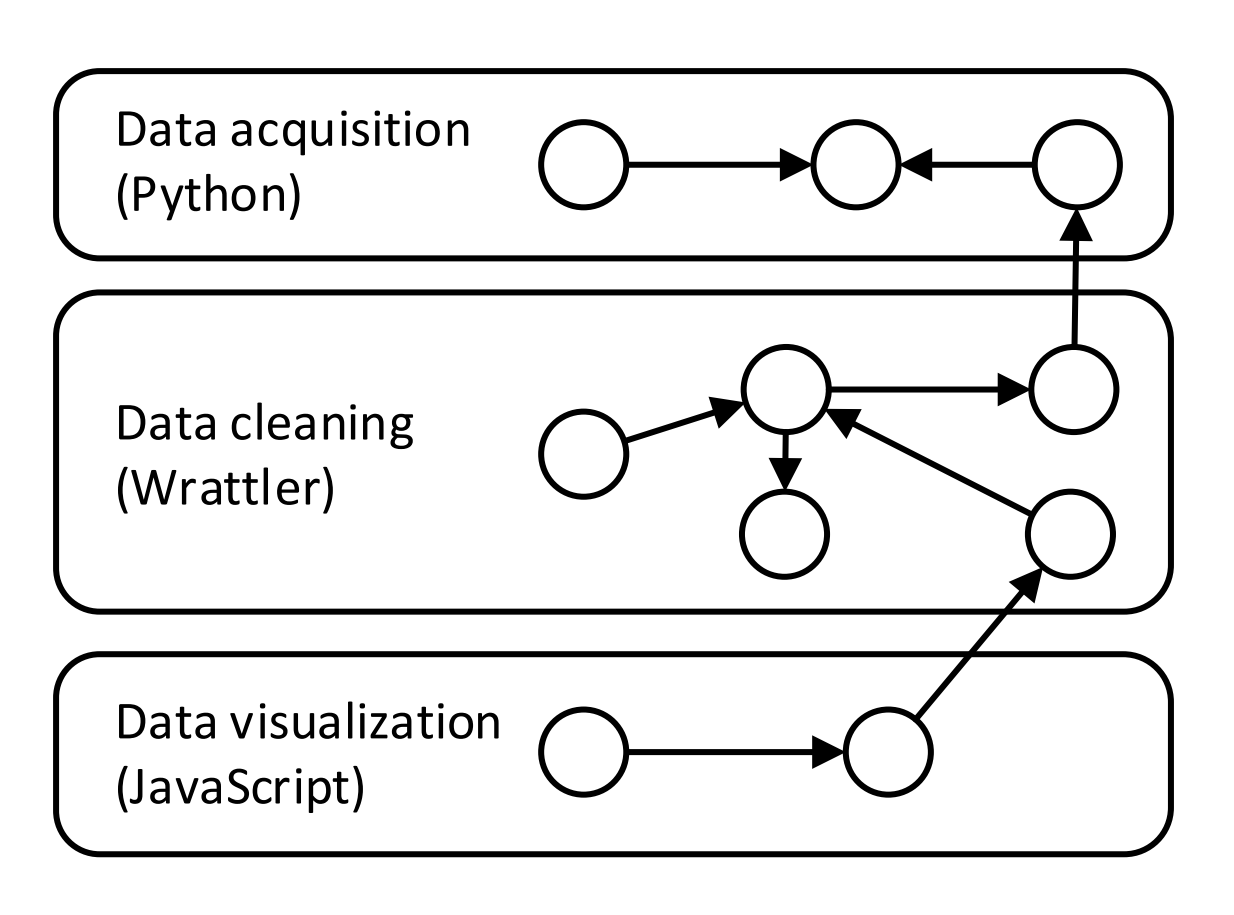
1 DEMO
Interactive – Exploring data in the browser
2 Smart
Simplifying process with AI assistants
Full access to data store
Domain specific languages
No black box magic
2 DEMO
Smart – Cleaning data with the datadiff assistant
3 Polyglot
Enabling platform for data science
Share data via data frames
Computation graph for provenance
Semantic annotations
3 DEMO
Polyglot – Sharing data between R and JavaScript
Summary
Interactive, smart and polyglot notebooks
Wrattler
Three key ideas behind the system
Separate state and language runtimes
Dependency graph in the browser
Platform for AI assisted data science
Project status
Wrattler prototype: github.com/wrattler
Done – Prototype with dependency graph running
R, JavaScript languages and datadiff assistant
Progress – Deployment as part of JupyterLab
Data store annotations and graph versioning
Visionary – Integration of further AI assistants
Provenance tracking, modes of interaction
Questions, answers & discussion
Data store – Best data and annotation formats?
Integration – Languages? Jupyter integration?
AI assistants – What kinds of assistants?
http://tomasp.net | tomas@tomasp.net | @tomaspetricek
To wrap up, I'll end with a slide that lists the three next papers that I plan to write. The first one is about implementing live programming environments, which is surprisingly tricky and the second one is extending the data aggregation work to cover data cleaning with AI assistants. Finally, I talked about one of the things that I'm interested in, but I also work on philosophy and history of programming and I got invited to submit a paper to an ACM HOPL conference, so that's my third. I have ideas about coeffects too, but I only wanted to list three.